There are many examples in the blogosphere of regressions run against the temperature record, the goal being to glean the effects of certain factors and the “true” warming signal, or even using this method for prediction. For this most recent warming period, I stumbled across ones from Tamino , Kelly O’Day , and Arthur Smith (which builds on Tamino’s analysis). An interesting note is Tamino’s analysis resulted in an estimated warming of about 1.5 greater than that of Kelly’s for UAH. I wanted to examine closer the choices that can lead to such a difference.
First, a few notes:
All code is available here, as well as an Excel spreadsheet highlighting the individual runs.
Data is automatically downloaded via the internet in the code. Much of the stuff I grab from Climate Explorer (http://climexp.knmi.nl/data/) because it is easy to work with: MEI, K&R Nino3.4, Sunspots, TSI, Multi-Model Mean.
I will be examining the period of January 1979 – January 2011. The start date I picked because that’s when the satellite indices start, and the end date is the last month of TSI reported at the time of starting this analysis. This differs slightly from both Tamino’s analysis (1975-2010) and Kelly O’Day’s (1979-Feb2011), although not enough to significantly alter the trends.
Also note that for the TSI dataset, some months are missing data along the way. For these I simply used an average of the two closest values to estimate. For the volcanic forcing from GISS, recent months are missing data and I assumed “0” for those.
1. First Glance at Results
| Dataset |
Raw Adj_R^2 |
Raw Trend |
2 Factor Adj_R^2
|
2 Factor Trend
|
3 Factor Adj_R^2
|
3 Factor Trend |
| NOAA |
0.60
|
0.160
|
0.72
|
0.157
|
0.74
|
0.176
|
| HadCRUT |
0.57
|
0.155
|
0.73
|
0.151
|
0.76
|
0.175
|
| UHA |
0.34
|
0.140
|
0.68
|
0.126
|
0.70
|
0.145
|
| RSS |
0.39
|
0.147
|
0.69
|
0.136
|
0.72
|
0.160
|
| GISS |
0.52
|
0.166
|
0.65
|
0.158
|
0.66
|
0.173
|
The trends above are all reported in C / Decade, and represent the supposed true warming signal with the exogenous factors removed. The “Raw” trend is just a simple linear regression against time. The 2 factor uses MEI + Volcanic, and the 3 factor uses MEI + Volcanic + TSI. I got similar lags to what has been reported by the aforementioned analyses: near instant solar (0-1 months for TSI), 3 month ENSO lag for surface and 5 month for satellite, and somewhere between 6-9 months for volcanic forcing lag.
What should be immediately obvious from above is that much of the difference in the true warming trend between Kelly O’Day’s regression versus Tamino’s can be attributed to the addition of a solar component. On the one hand, adding the solar factor would seem to make the model more complete, and does improve the adjusted R^2 value. On the other hand, the adjusted R^2 value is only modestly improved, but the additional variable has a large influence on the result. Furthermore, as I’ll discuss later, the regression underestimates the instantaneous volcanic forcing according to what we would theoretically expect, and the solar forcing appears to be overestimated. If we “corrected” these, the trends go down slightly.
I also want to point out that determining the proper model can be ambiguous. For instance, there might be < 0.01 difference in the adjusted r^2 value between the top 50 or so different runs, and with a noisy thing like the temperature set, using such miniscule differences to determine the “best” model is tricky.
2. MEI vs. Kaplan and Reynolds Nino3.4
One choice we have for the regression is using the Multivariate Enso Index vs. the Nino3.4 region SST. Bob Tisdale discusses a bit on the difference (although he uses HadSST instead of K&R) at the beginning of this post. A quick glance at the relevant time period and differences can be seen here:

Basically, in the first panel we can see the slight downward trend during this period. This means that removing the ENSO activity will generally make the factor-independent warming appear larger than one that does not attempt to remove ENSO activity. Or, the greater the assumed ENSO effect over this period, the more it is assumed to have masked the remaining warming.
The second panel highlights the differences in choosing the index – since MEI has a greater downward slope, choosing that index will make the “true” warming appear larger. The included spreadsheet has more details, but in my 2 factor analysis (volcanic and ENSO) I compared the results using these two different ENSO indices:
| |
Nino3.4 Adj_R^2 |
Nino3.4 Trend |
MEI Adj_R^2 |
MEI Trend |
| GISS |
0.645
|
0.148
|
0.652
|
0.158
|
| RSS |
0.683
|
0.121
|
0.69
|
0.136
|
| UHA |
0.673
|
0.111
|
0.682
|
0.126
|
| HadCRUT |
0.711
|
0.143
|
0.731
|
0.151
|
| NOAA |
0.709
|
0.150
|
0.716
|
0.157
|
Once again, the trends above are all reported in C / Decade, and represent the trend once the specified index and volcanic factors are removed. As can be seen, the trend is sensitive to the choice of MEI vs. Nino3.4 – particularly the satellites. While correlation appears better for MEI in all datasets, it should be noted that the actual Adj_R^2 are pretty close.
3. TSI vs. Sunspots
Another choice we can make, presuming we start in 1979 or later, is the choice of TSI vs. Sunspots to use to account for the solar factor. Once again, here is a graph of the two:

The first panel shows that the beginning of our period started out with higher solar activity, while the most recent years have low solar activity. The result of attempting to fit a linear trend, therefore, is one that shows a large down-slope. This explains why a regression that takes the solar factor into account will generally show an increased trend vs. time, or why a higher solar coefficient means a greater implied solar-independent warming trend.
Once again, I performed comparisons of using TSI vs. Sunspots for that third factor. The results are in the spreadsheet, but it was basically a tie with the adjusted R^2 values, with neither doing better in all datasets. Using sunspots consistently resulted in a larger estimate factor-independent warming, although only by a small margin (< 0.01 C/decade for all datasets) . Using the SD of TSI vs SD of sunspots over the period to scale, a sunspot would be equivalent to about .0082 W/M^2, and considering this factor the solar coefficient using sunspots was higher than its TSI equivalent – hence the slightly greater estimate of underlying warming.
4. The Volcanic Forcing
For this one, I only used the GISS index for stratospheric optical thickness (Tamino uses Ammann et. al. (2003) for his).

I’ve inverted the thickness value because it is a negative forcing. As we can see, the result over this period is a positive trend, meaning that the removal of this will decrease our apparent “true” trend. This explains why using only two factors (ENSO + volcanic) generally has a lower “true” trend than that raw calculation – the removal of the volcanic decreases this trend more than the ENSO removal increases it.
5. Stefan-Boltzmann Sense?
Tamino mentions that the response to the solar factor is greater than S-B predicts. A back of the envelope calculation yields 0.19 C/(W/m^2) (from S-B at current temperature, rather than simply using ~1365 for TSI) * 0.7 (albedo) / 4 (shadow area / surface area) = ~0.033 C expected immediate response per 1 W/m^2 change in TSI. A quick glance at the spreadsheet suggests the statistical model is estimating about 2-3 times that for surface record or satellite.
If we use the rough estimate for volcanic forcing based on optical thickness here, we get an expected response of approximately 0.19 C/(W/m^2) * -25 (W/m^2/tau) = ~-4.75 C/tau for our coefficient. For our surface datasets, we’re only getting about 33%-50% of that, and 75% of that for the satellite datasets.
The combination of the higher solar contribution and the lower volcanic contribution over this period results in a significantly higher estimate for the “true” warming trend than we would get if we used a simple physical model for these contributions.
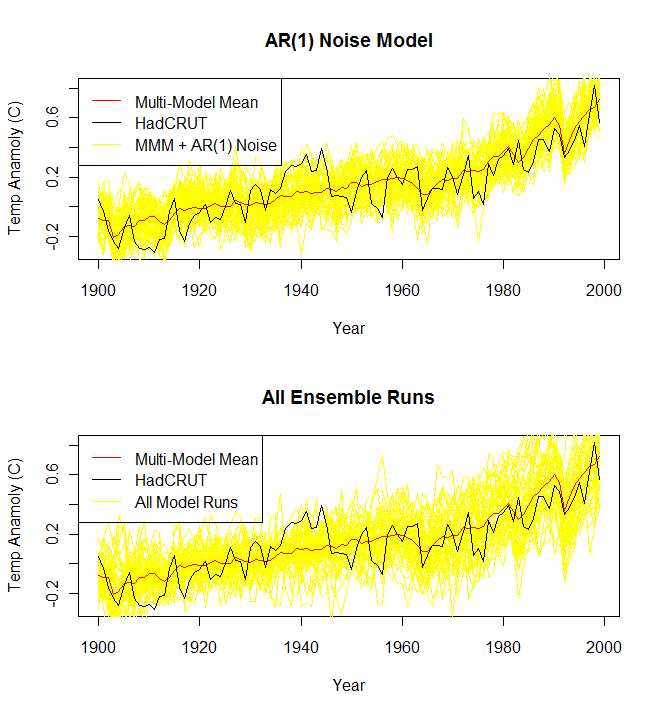
6. What do the models say?
I ran the same regression against the multi-model mean to see its immediate response to forcings (the results can be found in the spreadsheet as well). Since these are primarily physical models, it should give the expected physical response for volcanoes and solar factors…and since it neither simulates ENSO very well and the ENSO factor is not a forcing, the ENSO coefficient should be far smaller.
For the same time period (Jans 1979-2011), we get a significantly lower value for the solar coefficient (~.015) than we get for the actual observations, and even lower than S-B. However, it’s worth noting that the third of the period is in the 21th century, where actual historical solar and volcanic are not used. If I shift to only 1979-1999, we get a solar coefficient (~.036) that is approximately the expected value from S-B.
Also as expected, the ENSO component is almost non-existent – less than 10% of what we get for actual observations. However, the volcanic response is something of a surprise, staying considerably lower (~ -1.6 C/tau) and near the immediate response of the observations. This may suggest that rather than give an immediate response to a volcanic event, the multi-model mean smears the cooling over a variety of lag times (or even longer, on the scale of several years), such that it is difficult to tease out.
7. Another time period
I tried running the regression on some other time periods, such as 1900-1950 and 1910-1940 on HadCRUT, with the results in the spreadsheet. This period seems like it would be relatively straight-forward based on the graph of estimated GISS model forcings. I had to use sunspots and Nino3.4 since those go back further in time than TSI or MEI. The results are also in the spreadsheet. On the one hand, the calculated ENSO factor had about the same effect as during the modern warming period. On the other hand, the volcanic and solar lags and coefficients were all over the place, even changing signs, depending on what portions of the early 20th century were included. The adj_R^2 values are significantly lower, so I’m not sure if the weird results are due to more noise and uncertainty specifically in the early 20th century observations, or if generally the regressions run on thirty year periods are limited in determining responses to volcanic and solar forcings.
Going back to the multi-model mean, running on the 1910-1940 period gives a better correlation than against the observations, with a significantly lower ENSO factor yet again. And, while the lags are a bit more variable, we get a volcanic coefficient (~-2.5) and solar coefficient (adjusted to TSI, ~0.022) that at least appear somewhat reasonable. Not surprising given that it should be using about the same physical model throughout.
8. HadCRUT Pure Statistical Model vs. Some Physical Components
Below, I show the different modeling approaches against the observations. For the top red line, it uses the “pure” statistical model with the optimized lags. For the two lines below that, I used the estimated theoretical values from S-B substituted in for the statistical estimates (only solar in one case, both solar and volcanic in the other case). I should note that the lags in these lower to lines have not been fitted based on the new coefficients, so it might be possible to lower the RMSE for those with better fit lags.

The standout appears to be that larger volcanic response. The trouble is that if the lag is off for a few months with the high volcanic sensitivity, it ends up failing spectacularly, greatly increasing the error. I think this is why a statistical model that assumes the lag in response to a volcanic forcing is always going to be the same will always tend to underestimate the magnitude of this response.
Anyhow, the above also demonstrates the sensitivity of the estimated “true” warming to assumptions about the effects of other factors. It is worth pondering to what degree a statistical model over this period has the ability to accurately capture the magnitude of smaller effects – such as the solar component – vs. noise. I may look into that in a future post.















{kind=link}